

Pandas - Data Science
Introduction
I have recently come across a lot of aspiring data scientists wondering why it’s so difficult to import different file formats in Python. Most of you might be familiar with the read_csv() function in Pandas but things get tricky from there.
How to read a JSON file in Python? How about an image file? How about multiple files all at once? These are questions you should know the answer to – but might find it difficult to grasp initially.
And mastering these file formats is critical to your success in the data science industry. You’ll be working with all sorts of file formats collected from multiple data sources – that’s the reality of the modern digital age we live in.

So in this article, I will introduce you to some of the most common file formats that a data scientist should know. We will learn how to read them in Python so that you are well prepared before you enter the battlefield!
I highly recommend taking our popular ‘Python for Data Science‘ course if you’re new to the Python programming language. It’s free and acts as the perfect starting point in your journey.
5. Read the following file formats using pandas
a. Text files
Text files are one of the most common file formats to store data. Python makes it very easy to read data from text files.
Python provides the open() function to read files that take in the file path and the file access mode as its parameters. For reading a text file, the file access mode is ‘r’. I have mentioned the other access modes below:
- ‘w’ – writing to a file
- ‘r+’ or ‘w+’ – read and write to a file
- ‘a’ – appending to an already existing file
- ‘a+’ – append to a file after reading
Python provides us with three functions to read data from a text file:
- read(n) – This function reads n bytes from the text files or reads the complete information from the file if no number is specified. It is smart enough to handle the delimiters when it encounters one and separates the sentences
- readline(n) – This function allows you to read n bytes from the file but not more than one line of information
- readlines() – This function reads the complete information in the file but unlike read(), it doesn’t bother about the delimiting character and prints them as well in a list format
Let us see how these functions differ in reading a text file:
 by
by 
The read() function imported all the data in the file in the correct structured form.
![]()
By providing a number in the read() function, we were able to extract the specified amount of bytes from the file.
![]()
Using readline(), only a single line from the text file was extracted.
Here, the readline() function extracted all the text file data in a list format.
b. CSV files
Ah, the good old CSV format. A CSV (or Comma Separated Value) file is the most common type of file that a data scientist will ever work with. These files use a “,” as a delimiter to separate the values and each row in a CSV file is a data record.
These are useful to transfer data from one application to another and is probably the reason why they are so commonplace in the world of data science.
If you look at them in the Notepad, you will notice that the values are separated by commas:

The Pandas library makes it very easy to read CSV files using the read_csv() function:

But CSV can run into problems if the values contain commas. This can be overcome by using different delimiters to separate information in the file, like ‘\t’ or ‘;’, etc. These can also be imported with the read_csv() function by specifying the delimiter in the parameter value as shown below while reading a TSV (Tab Separated Values) file:
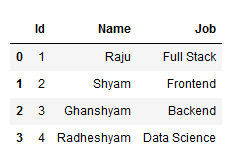
c. Excel files
Most of you will be quite familiar with Excel files and why they are so widely used to store tabular data. So I’m going to jump right to the code and import an Excel file in Python using Pandas.
Pandas has a very handy function called read_excel() to read Excel files:

But an Excel file can contain multiple sheets, right? So how can we access them?
For this, we can use the Pandas’ ExcelFile() function to print the names of all the sheets in the file:
![]()
After doing that, we can easily read data from any sheet we wish by providing its name in the sheet_name parameter in the read_excel() function:

And voila!
d. JSON files
JSON (JavaScript Object Notation) files are lightweight and human-readable to store and exchange data. It is easy for machines to parse and generate these files and are based on the JavaScript programming language.
JSON files store data within {} similar to how a dictionary stores it in Python. But their major benefit is that they are language-independent, meaning they can be used with any programming language – be it Python, C or even Java!
This is how a JSON file looks:

Python provides a json module to read JSON files. You can read JSON files just like simple text files. However, the read function, in this case, is replaced by json.load() function that returns a JSON dictionary.
Once you have done that, you can easily convert it into a Pandas dataframe using the pandas.DataFrame() function:

But you can even load the JSON file directly into a dataframe using the pandas.read_json() function as shown below:


0 Comments